pgModeler 0.9.2-beta2 is ready!
Foreign tables support is now a reality.
2019
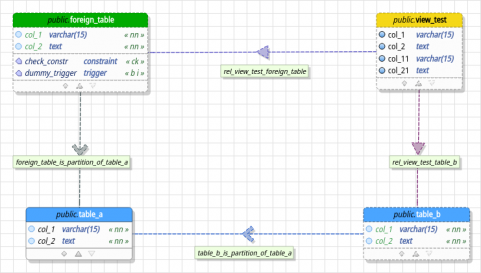
The development of this new version was strongly focused on delivering the support to foreign table objects. This way pgModeler is now capable of handling all foreign objects implemented by PostgreSQL. There was other important improvements including the support to diff presets which lets the user to configure a set of options enabled/disabled for the diff operations. Due to the release of PostgreSQL 12 some patches were applied to pgModeler in order to allow the users to connect to database servers of that version. This will allow all operations that depends on connections like export, diff, import to be performed on newer versions of PostgreSQL. Finally, lots of bugs were fixed too including crashes, false-positive results on diff feature and some problems on reverse engineering that was causing some kind of objects to be imported wrongly. All key changes of the release are fully detailed in this post. Keep reading!
What's new on pgModeler 0.9.2-beta1
Fixes and improvements in preparation for the stable 0.9.2.
2019
This release brings a few improvements as we're starting to deaccelarate the development of new features and concentrating on minor changes and bug fixes until the stable 0.9.2 is done. The main focus was to improve the data manipulation form, fix some small UI problems and bugs detected previously on 0.9.2-beta. There were fixes on the file saving procedure as well to the diff process when dealing with timestamptz columns and minor changes to a small set of feature in the design view. See details in the full post!
A step closer to the 0.9.2 stable: the first beta of this series is ready!
Foreign data wrappers, foreign servers and user mappings are now fully supported.
2019
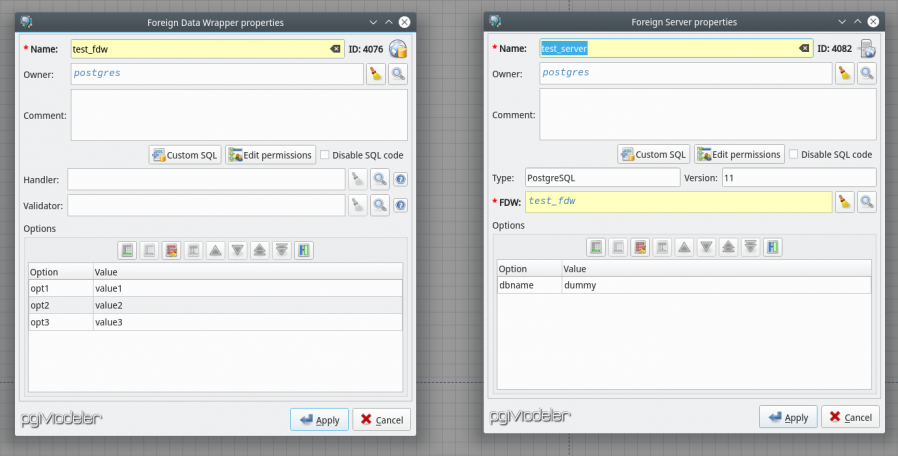
This release brings some important features requested long ago and several patches to improve the overall tool's usability. pgModeler now supports foreign data wrappers, foreign servers and user mappings natively. Foreign tables, for now, aren't supported but in order to provide a temporary workaround for this lacking the generic SQL objects were improved in such way to store references to another objects in the model which helps to keep track of name changes and giving a touch of dynamicity to that kind of object. Another improvement is the ability to quickly filter the result set retrieved from a SQL command in the SQL execution without the need of rewrite the SQL command to get the desired data. This release also brings some changes in the available features: the first one is the ability to search for objects in the canvas by matching other attributes not only the name. For instance, you can search items by matching a keyword against object's comments, data types, schemas and some others. A second change is the categorization of the action "New object" in order to diminish the amount of items displayed in the same menu and organizing object types hierarchically. Finally, for the bug fixes, in this version they fix mainly crashes and broken code generation as well improve the objects handling in the canvas. Read the complete post to see the details about pgModeler 0.9.2-beta!
Yeah! pgModeler 0.9.2-alpha1 is ready bringing lots of news!
Table partitioning, canvas layers, view's columns and much more.
2018
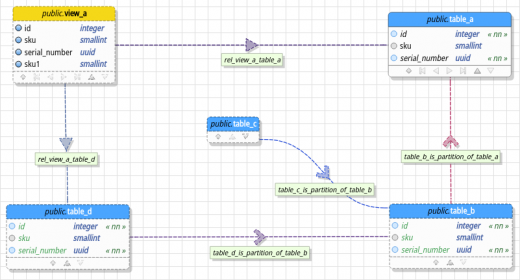
Finally, after four months, we have a new version out of the oven! This one has A LOT of changes that range from several code refactoring and performance improvements to the introduction of new interesting features like table partitioning and canvas layers. First, let's talk about the changes and improvements. The objects drawing operations received a good set of patches making it a bit faster and less memory consuming. The overall performance of the reverse engineering was improved which, in consequence, have enhanced the diff process performance as well. In the new features side, we added scene layers which goals is to introduce a new level of visual segmentation of graphical objects. Another new feature created is the support to view columns that are deduced from the relationships between these objects and the tables. In the design view, in order to be more close to the new features introduced by PostgreSQL 10+, pgModeler is now capable of handling declarative table partitioning. Besides, tables and views can have their attributes paginated or even collapsed to minimize the area occupied by them making big objects easier to visualize. Finally, about the bug fixes, several crashes were eliminated making the tool more stable for different usages, the reverse engineering received some patches so it can import correctly user-defined types in form of arrays and many others. This post will try to explain some of these changes and new features in details. Check it out!
pgModeler 0.9.2-alpha is out!
A new development cycle started, lots of new things to come!
2018
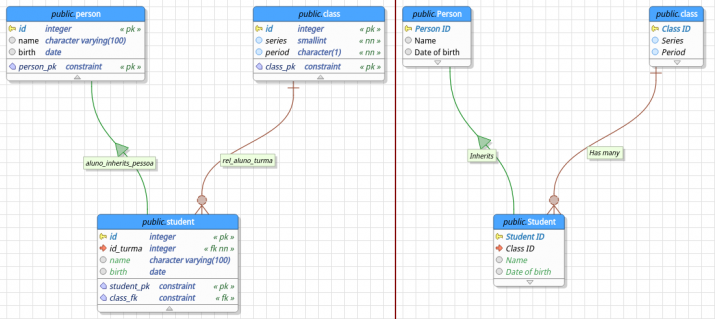
This release does not have an extensive change log but brings some long desired features as well important fixes. Some of the new features to highlight in this post are: the long awaited SQL execution cancelling feature, the compact view for a more friendly visualization of the database model, the ability to save and restore the majority of dialogs sizes and their positions and many others. Talking about bug fixes we have a small set of corrections that solved crashes as well the generation of malformed SQL commands in certain situations increasing the reliability of the tool. What is more important now is that, after staying a bit away from the project, I'm back to the road to introduce a series of new features that'll prepare pgModeler to its biggest release: the version 1.0. This is a slow work but we'll get there.
pgModeler 0.9.1-alpha1 is ready!
PostgreSQL 10 support fixes, improved DB diff and other small changes
2017
This second alpha release brings minor improvements and small fixes being the last version released this year. Some importing issues related to PostgreSQL 10 were fixed and now the users can import their databases without much problem. The diff tool was enhanced in such way that now is possible to compare two databases and not only a model and a database. There were some changes on the database design view like the ability to create relationships more easily and the ability to fade in/out the objects in the result set of the object finder tool. More details in the full post, good reading!
pgModeler 0.9.1-alpha is here!
Crow's foot notation is the cutting-edge feature this time.
2017
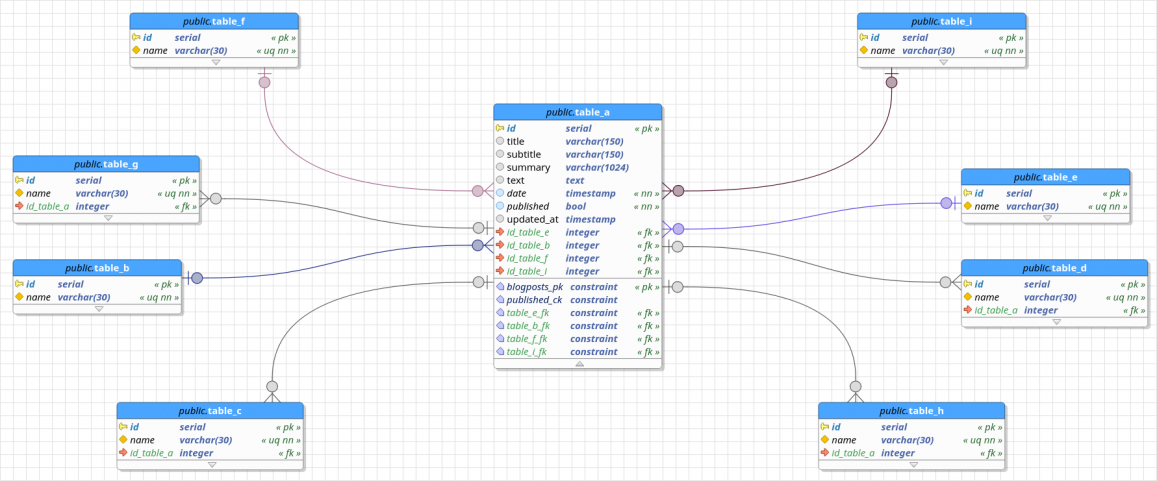
This release opens the path to the new major release 0.9.1 bringing some new features based upon old requests, improvements to current features and fixes for bugs reported after the launch of 0.9.0 last month. This first alpha branch finally introduces the Crow's foot notation adding an improved readability to the database models. The support is still quite experimental and has some limitations that can be removed in future releases. Another enhancement done in the tool is the ability to toggle schemas' rectangles at once without the need to do it object per object. A new automatic arrangenment algorithm was introduced and causes tables to be scattered inside their respective schemas and then scatter the schemas themselves, this will serve as a starting point for users to arrange their tables over the canvas. See the full post for more details.
Another development cycle is closed: pgModeler 0.9.0 is ready!
One year of hard work to bring an amazing release.
2017
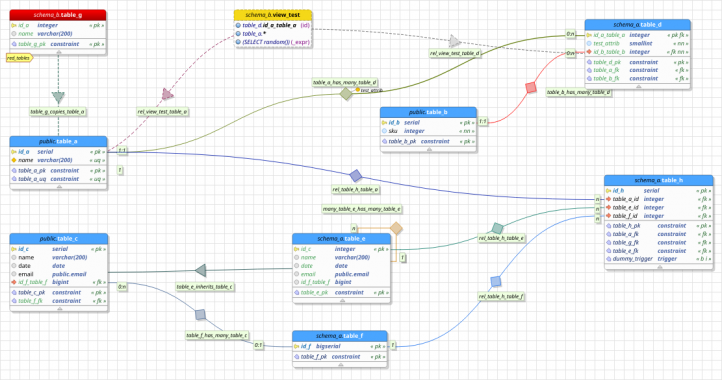
After one year and three months of hard work I proudly present you the pgModeler 0.9.0. This version does not bring extraordinary changes or improvements compared to the previous alphas and betas but it closes one more development cycle delivering an even more refined product to our users keeping the main purpose of this project in mind: create a quality open source software. In order to give an idea on how this project have changed since last year, or since 0.8.2, if we place together all change log entries from the beggining of the 0.9.0 development we would have: 175 entries being them 51 new features, 58 changes/improvements and 68 bug fixes. These numbers only indicates how this project is being constantly enhanced through the years. In this post I'll briefly describe what's new, don't miss it!
pgModeler 0.9.0-beta2 is out!
Auto arrangement, improved zooming tools, several fixes and much more!
2017
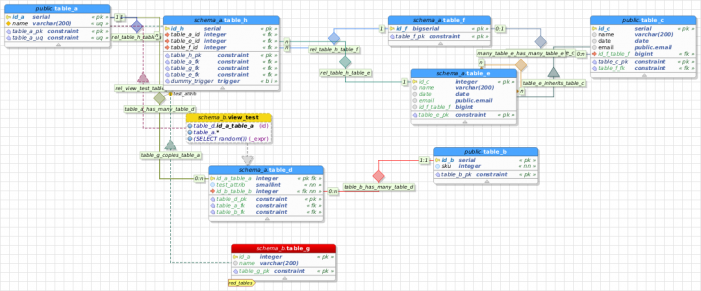
This release was meant to be the final 0.9.0 but due to the several changes, bug fixes and new features introduced it was more prudent to bring it as the second beta instead of the stable version so we could gather as many as possible feedbacks and fix any remaining issue in order to finally launch the pgModeler 0.9.0 stable. The new pgModeler brings lots of new features mainly related to the database modeling, but there are several changes and fixes in other areas of the software that will make it even more reliable and easy to use.
What's new on pgModeler 0.9.0-beta1
Experimental hi-res support, improved data handling and much more!
2017
This is the last release before we can finally launch the stable 0.9.0. The development of this version was mainly focused on improving the user's experience on high resolution monitors by introducing an automatic machanism that is capable to resize dialogs, objects and fonts according to the current screen settings. This support is quite experimental and will be polished in the next releases. Another feature introduced was the support to browse the referenced rows as well the referrer rows in data manipulation dialog which will improve the the whole data handling experience. How these features work, their drawbacks and limitations are fully explained in this post. Don't miss it!