Hooray! pgModeler 1.2.0-alpha1 is here!
Lots of enhancements aiming at productivity increasing.
2024
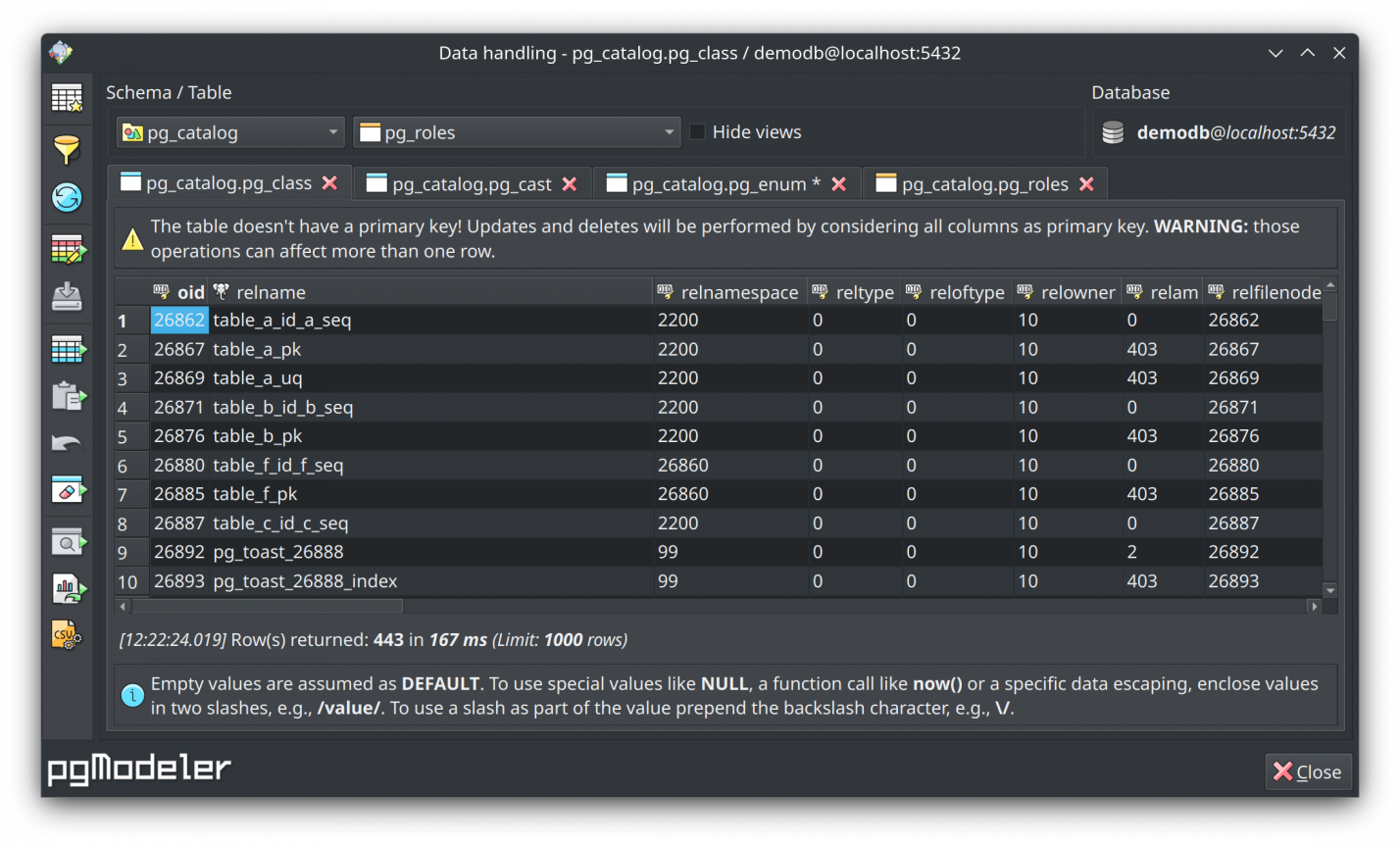
After 4 months of work, I'm quite happy to announce another release of our beloved PostgreSQL database modeling tool! This version brings 23 new features, 22 improvements, and 14 fixes since the release of the previous alpha. This time, some important decisions were taken to make the code base a bit less complicated to maintain, at the same time some other portions of the tool were refactored to allow plugins' development to be more flexible. New features and important changes are also included, and I hope they will improve the tool's usage. Briefly speaking, this release introduces some nice features that can help in productivity. In the database modeling process, 1.2.0-alpha1 introduces a new way to quickly configure and assign layers to objects. The SQL export operation can be executed in a transaction block for atomic command executions, reverting changes if a single error occurs. In the SQL execution widget (in the management view), the code completion widget is now triggered for ALTER/DROP commands. Also, we're presenting the support for query variables which facilitates the test of queries using different variable formats adopted by ORMs. Finally, the data handling form received an important patch and now reunites the browsed tables in tabs drastically diminishing the use of standalone windows which could be confusing for the users. Everything will be fully explained in the full post, don't miss it!
pgModeler 0.9.4-alpha is finally ready!
Multiple layers support, custom canvas colors and much more.
2021
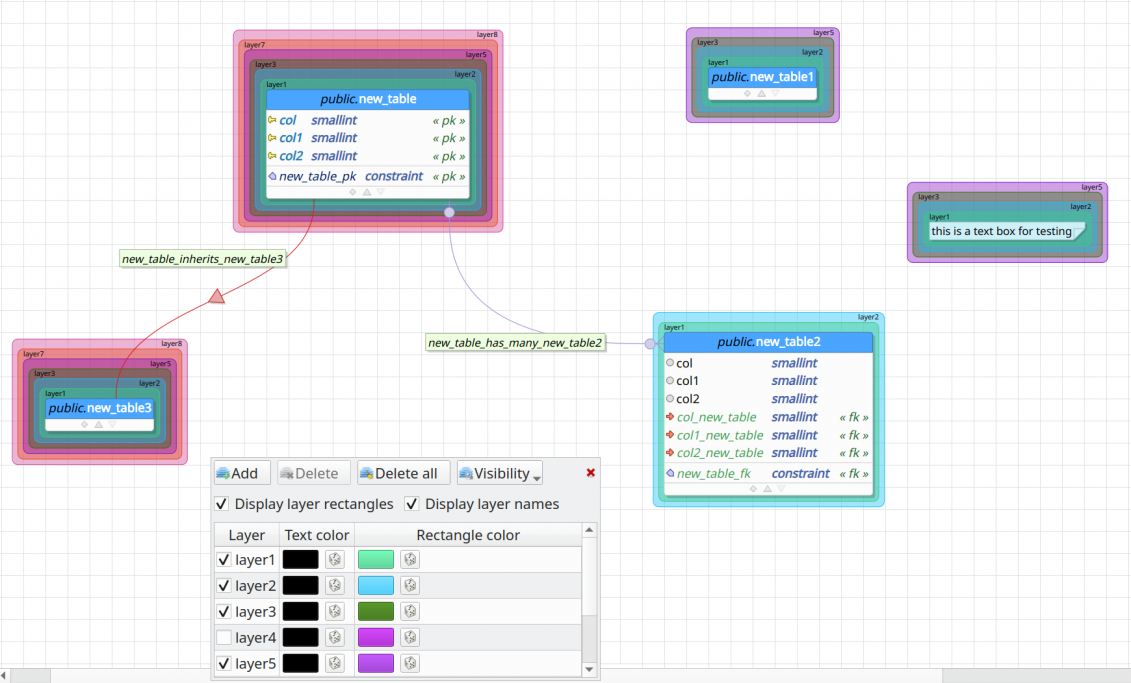
It took almost half-year to conclude the first alpha release of 0.9.4 due to several problems I was facing. Anyway, I kept working on pgModeler at a slower pace and releasing snapshot buildings until we had reached an acceptable state of maturity for an alpha release. The main improvement of this version is the support for multiple layers as well as custom colors for these entities. Additionally, we have added the ability to change the colors of the canvas elements: grid lines, background color, and page delimiter colors. Functions and procedures can now use custom configuration parameters and transform types. Finally, there were important fixes too, which include the fix to the malformed SQL code related to triggers and functions, several patches in the database importing feature, the correct loading of changelog entries registered in a database model file, and much more. In this post I'll describe some of the improvements in detail, so don't let to read it!
Yeah! pgModeler 0.9.2-alpha1 is ready bringing lots of news!
Table partitioning, canvas layers, view's columns and much more.
2018
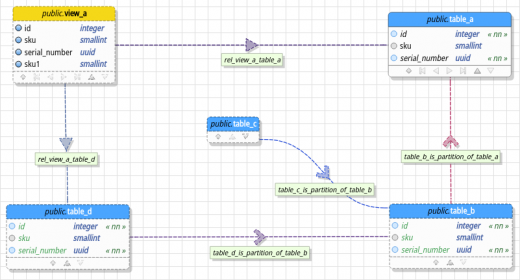
Finally, after four months, we have a new version out of the oven! This one has A LOT of changes that range from several code refactoring and performance improvements to the introduction of new interesting features like table partitioning and canvas layers. First, let's talk about the changes and improvements. The objects drawing operations received a good set of patches making it a bit faster and less memory consuming. The overall performance of the reverse engineering was improved which, in consequence, have enhanced the diff process performance as well. In the new features side, we added scene layers which goals is to introduce a new level of visual segmentation of graphical objects. Another new feature created is the support to view columns that are deduced from the relationships between these objects and the tables. In the design view, in order to be more close to the new features introduced by PostgreSQL 10+, pgModeler is now capable of handling declarative table partitioning. Besides, tables and views can have their attributes paginated or even collapsed to minimize the area occupied by them making big objects easier to visualize. Finally, about the bug fixes, several crashes were eliminated making the tool more stable for different usages, the reverse engineering received some patches so it can import correctly user-defined types in form of arrays and many others. This post will try to explain some of these changes and new features in details. Check it out!