5.3. Compare model and database
The comparison or diff process in pgModeler consists of generating a set of SQL commands that will make both the model and database synchronized. In the most recent versions of the tool, there's a possibility to compare two databases as well. In detail, the comparison is made from model to database, meaning that any object existing in the model and absent in the database will be created. In the same analogy, any object absent in the model and present in the database will be destroyed in the latter. The key idea here is that the model is the main reference meaning that any change made to the database that is not in the former is completely ignored. This is useful to keep the model always up-to-date because the user needs to alter first that one and then apply the changes to the database.
The process itself is quite simple, first, pgModeler will generate a temporary model based on the database to be compared using the reverse engineering feature. Once generated the model it's time to compare the objects from the input model (the reference) and the ones present in the temporary one. Any detected difference is stored and processed later resulting in a set of SQL commands that may create new objects, destroy old ones, or just alter the structure of the current ones. When the comparison finishes, the commands are ready to be applied to the database. At this moment, depending on the settings defined by the user, the generated commands will be saved in a file or exported directly to the server. In the case of exporting to the server, the user will be prompted to proceed with the irreversible changes to be done to the database. Before confirming the modifications it is highly recommended to make a backup of the database in case something goes wrong.
The diff presets allow the user to save different settings and reuse them whenever needed. This is useful when you need to run the diff process in every stage of software development, let's say, development, homologation, and production. On each of these stages, you may use different diff settings depending on your needs. For instance, in development and homologation, you can force the recreation of objects or even drop objects in cascade mode, but the same options can't be used in the production stage for security reasons. So, with this feature, pgModeler allows you to vary the options used in the diff for different contexts.
Finally, the model-database diff dialog has a long set of options and they may affect how the resulting commands are generated as well as their semantics. You seldom need to change their values but in a few cases, the default settings can't generate the diff as expected so you'll need to tweak them to achieve the desired result. Below all available options are fully described. This feature is still in experimental state and may produce false-positive results or extra/redundant code in the final code, but these issues are being solved little by little. Another limitation of the diff process is that the object's renaming in the model can't be detected and instead of issuing an ALTER ... RENAME command on the diff script the object with the old name will be dropped, so be extremely careful when doing diffs!
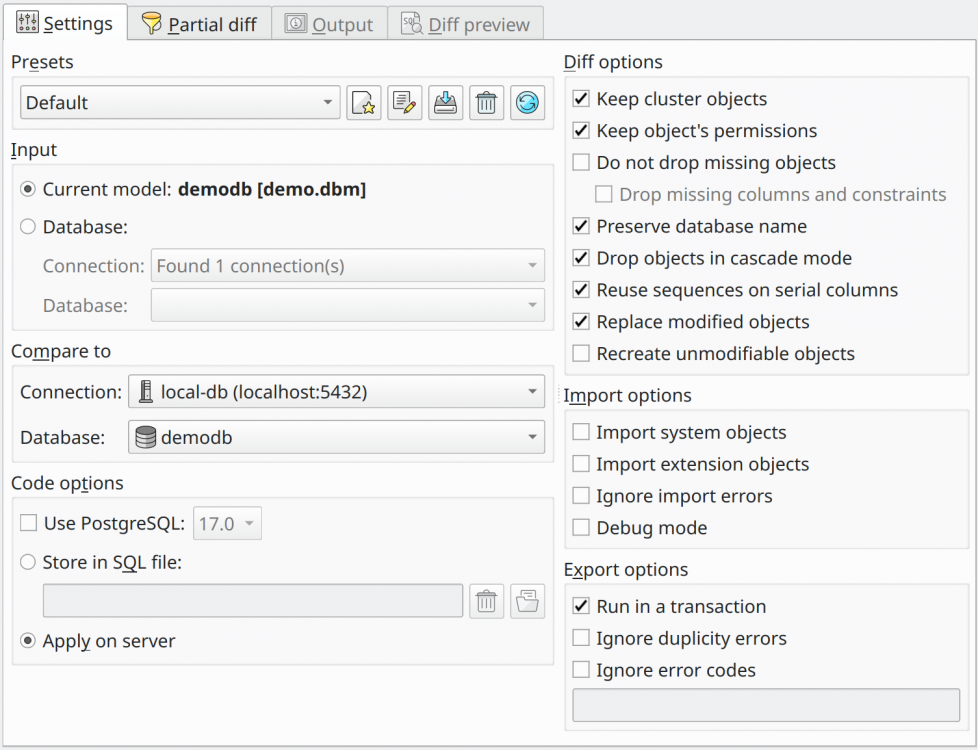
Presets
| Option/Field | Description |
|---|---|
Presets list |
This combo box lists the loaded diff presets. |
Add new preset |
Triggered by Ins this action starts the saving of a new preset based on the currently selected options checked in the dialog. |
Edit preset name |
Triggered by Ctrl + E this action is used to rename the selected preset. |
Save preset |
Triggered by Ctrl + S this action saves the currently selected options in the form to the selected preset. |
Delete selected preset |
Triggered by Del this action deletes the currently selected preset. |
Restore default presets |
Triggered by Ctrl + R this action restores the default presets causing all user-defined preset to be deleted. |
Input
| Option/Field | Description |
|---|---|
Current model |
The working database model used as input of the diff process. |
Database |
If you intend to compare two databases instead of a model and a database you can select this option and choose a connection on the field Connection to browse the desired database. Once connected to the server, the combo box Database will list all available databases to be used in the comparison. Note that the user credentials configured in the selected connection must own the needed permissions to query the system catalogs and manage objects or the process will certainly fail. |
Compare to
| Option/Field | Description |
|---|---|
Connection |
Previously configured connection used as a communication channel to the server where to look for the database compared against the input model or database. This connection also needs to be configured with a user with the needed permissions to query the system catalogs and manage objects. |
Database |
The database selected here is the one that will be compared to the model or database selected in the Source database field. |
Diff mode
| Option/Field | Description |
|---|---|
Use PostgreSQL |
Override the PostgreSQL version when generating the diff code. The default is to use the same version as the input database (detected automatically). |
Store in SQL file |
Compares the model and the input database storing the diff in an SQL file for later usage. |
Apply on server |
Compares the model and the input database generating a diff and applying it directly to the latter. This mode causes irreversible changes in the database and in case of failure the original structure is not restored, so make sure to have a backup before proceeding. |
Diff options
| Option/Field | Description |
|---|---|
Keep cluster objects |
Database cluster-level objects like roles and tablespaces will not be dropped. |
Keep object's permissions |
Permissions already set on database objects will be kept. The ones configured on the model will be applied to the database. |
Do not drop missing objects |
Avoid the generation of DROP commands for objects that exist in the database but not in the model. This is useful when diffing a partial model against the complete database. |
Drop missing columns and constraints |
Force the generation of DROP commands for columns and constraints that exist in the database but not in the model. This is useful when diffing a partial model against the complete database and the user needs to drop columns and constraints but preserves the rest of the objects. |
Preserve database name |
No command to rename the destination database will be generated even if the model's name differs from the database name. |
Drop in cascade mode |
For DROP command, the objects that depend on an object to be dropped will be deleted as well. For TRUNCATE command, tables that are linked to a table to be truncated will be truncated too. This option can affect more objects than listed in the output of diff preview. |
Reuse sequences on serial columns |
Serial columns are converted into integers and have their default values changed to nextval(sequence) function call. By default, a new sequence is created for each serial column but checking this option sequences matching the name on the column's default value will be reused and will not be dropped. |
Replace modified objects |
If an object being flagged as changed supports the CREATE OR REPLACE syntax, pgModeler generates the proper command to replace the object instead of dropping and recreating it. Currently, this is applied to aggregates, functions, languages, procedures, rules, transforms, triggers, and views. NOTE: this option takes precedence over Recreate unmodifiable objects when the object type is one of the above list. |
Recreate unmodifiable objects |
Recreates only objects that can't be changed through ALTER commands according to pgModeler implementation, not the PostgreSQL one. Currently, those objects are aggregate, cast, constraint, collation, conversion, language, operator, operator class, operator family, rule, trigger, and view. |
The options available in the tab Import & Export are the same ones used by the import and export processes so the details about them can be seen in the previous sections in this chapter. After configuring the desired options you can start a diff process by hitting the button Generate. The whole process can take a long time due to the number of comparisons done and the size of the involved model and database. Unlike the import, the diff dialog will not be closed automatically at the end of the process because the user can compare other databases to the model using the current settings.
5.3.1. Partial diffs
This feature consists of taking an input database or model, applying user-provided filters, and diminishing the number of objects to be compared. This brings us a significant gain of speed in the whole comparison process because only a subset of the database/model will be handled. The partial diff has two ways of filtering objects: 1) through the user-provided filters like the ones used in the reverse engineering; 2) by using the database model changelog to filter automatically the modified objects.
In order to use the partial diff through manual filtering, there's the need to specify a set of object filters composed of the object type and a search pattern (wildcard string or regular expression). Once all the filters are set it's time to retrieve the objects matching them, which is done by clicking Apply in the filter widget. All matching objects will be listed in the Input grid at the right of the Partial diff tab. Now, just click Generate to start the partial diff process.
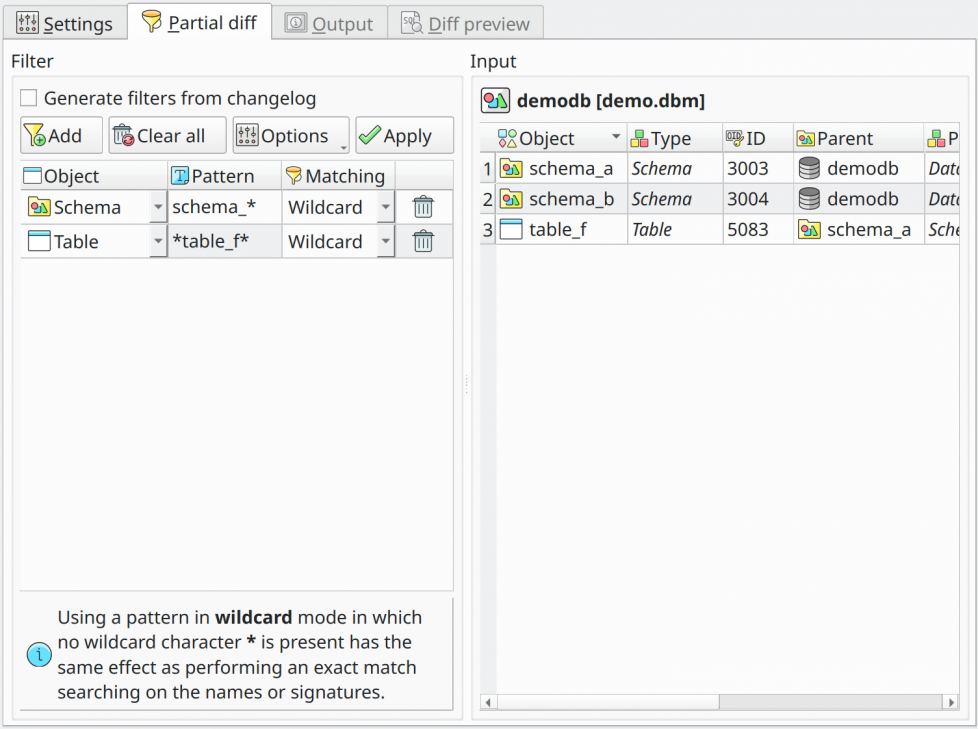
Now, in order to use the filtering based on the model's changelog one needs to check the option Generate filters from changelog and the filter widget will display the fields as shown in the image below. After that, the user just needs to specify a date/time interval that will be matched against the changelog, click the button Generate filters, and then retrieve the modified objects by clicking Apply. Internally, pgModeler generates, based on the objects found, filters like the ones in the below image using object signatures as the filter patterns. These filters are then used in the whole partial diff process so the correct result can be produced.

Despite the huge improvement in the diff operation with the introduction of the partial comparison the process still has its deficiencies. For instance, the diff isn't able to detect objects moved between schemas, let's say, schema_a.table to schema_b.table, in this case, the diff will always understand that schema_a.table was dropped and schema_b.table was created.